Marketing Data Science - Case Studies from Airbnb, Lyft, Doordash


In the first quarter of 2019, Airbnb spent $367 million on sales and marketing. When you think about this from a technical standpoint, two obvious problems come to mind:
- How do you scale your marketing processes to be able to spend $300+ million per quarter on ads?
- Once you have systems in place to spend huge ad budgets, what's an optimal way to allocate the money?
In this article we'll look at several case studies of data science in marketing, applied to optimize efforts at companies like Lyft, Airbnb, Netflix, Doordash, Wolt, Rovio Entertainment.
Summarizing articles from official blogs of these companies, we'll get a high level overview of marketing automation and then zoom in on the parts where data science and machine learning play their role.
If you read on, you'll find these three sections:
- Marketing automation systems - what are they, what subsystems they comprise, where in the process is data science usually applied
- Performance estimation - why estimating the performance of your campaigns is the fundamental problem in marketing analytics and what is the data science tool set used for this
- Optimizing bidding and budget allocation - once your marketing efforts are at the scale of hundreds or thousands of concurrent campaigns, it's impossible to allocate you budget manually in an optimal way. This is where Marketing Data Science shines. We look at two simple algorithms for budget allocation, shared by DoorDash and Lyft engineers.
Marketing Automation Systems
In large and analytically mature organizations, the optimization piece usually comes as a part of a larger marketing automation system, but as we'll see it's not always the case. Allocating budgets manually but aided by data science can be hugely profitable and might be a good first step towards a fully automated workflow.
Before diving into details, let's look at high level architecture of an automated process for online marketing.
Generally, all advertising platforms involve a common workflow. You set up the ad creative (text, visuals), choose the target audience, set bidding budget and strategy. As a result of streamlining this workflow, marketing automation systems are very similar in their high level architecture. Usually, these systems comprise the following:
- Data tracking system
Track conversion events (customer signups, payment events, subscriptions, micro-transactions, etc). - Attribution system
Connect conversion events with the user acquisition source. That is, for each user we want to know exactly the marketing channel and the campaign that brought them in. - Performance estimation system
Let's say a campaign brought in 1000 users. We want to know if it paid off. We know how much we spent on it, but how do we know how much revenue the users will bring us over their lifetime. LTV and conversion modelling comes into play here. - Campaign management system
Online ads are a very fertile field for variation testing and content generation. But even without testing multiple you variations of the same ad, companies typically target different segments in different ways, easily resulting in dozens or hundreds ads running simultaneously. Companies like Airbnb and Netflix invest heavily in systems that support ad creation and management ( Airbnb article, Netflix article). - Automated bidding and budget optimization
The largest ad serving platforms provide you with near real-time feedback on your ad performance. Connect this with the spend and projected LTV and you can get your ROI predictions and adjust budgets accordingly. With dozens or hundreds of campaigns and variations, the benefits of automation and optimization at this steps can be huge.
As we're interested in the role that data science can play in overall ad lifecycle, we'll focus on the two parts that tend to benefit the most from mixing in data science: 1) performance estimation and 2) automated bidding and budgeting.
Before diving in, it's important to understand the channel/campaign nomenclature. By channel we consider an advertising platform, such as Google AdWords, Facebook, Youtube, etc. A campaign is a single piece of advertising aimed at specific audience, according to segments available on the channel, with a preset starting and end time.
When evaluating marketing performance, we might want to look at investment and ROI at the level of a channel, a single campaign or a group of similar campaigns. We'll see how these different levels of granularity influence the amount and quality of available data, and in consequence how that determines the approaches that can be taken.
Performance Estimation
Ideally, for the purpose of marketing data science optimization we're interested in LTV and CAC (Customer Acquisition Cost) as the factor in the ROI equation: $$ROI=\frac{LTV}{CAC}$$
LTV modelling is a fundamental problem in business analytics and it is far from trivial to get it completely right. The exact models depend heavily on the type of business and the intended application. LTV models are generally more valuable if we can give good estimates very early in the user lifetime. However, the earlier we do it the less data we have at our disposal.
In Pitfalls of Modeling LTV and How to Overcome Them, Dmitry Yudovsky outlines several challenges that make it impossible for a cookie-cutter approach for LTV estimation to exist:
- Machine learning approaches are sometimes completely inadequate.
There might be lack of data necessary for long term LTV predictions. Also, even if we do have a large business with tons of historical data, there are cases when training models on year old data doesn't work well - maybe the product or the entire market is very different than a year or two ago. - Depending on whether we want to use LTV estimates for ad optimization, CRM efforts or corporate financial projections, we might have different requirements for model accuracy and cohort granularity at which we're making predictions (eg. single user, single campaign, group of campaigns, all users, etc.)
Of course the problem is not intractable, and there are several common approaches. We'll look at a few case studies found in tech blogs from DoorDash, Airbnb and Lyft Engineering teams.
In Optimizing DoorDash’s Marketing Spend with Machine Learning, Doordash data scientists present their approach, where instead of directly estimating LTV, they model conversion rates as a function of marketing spend. We'll see later how these cost curves help to neatly optimize budget allocation across channels and campaigns.
Experience (data) tells us that any marketing channel will reach saturation at some point, so we can model cost curves, ie. $Conversion=f(Spend)$ using a power function of the form $a\cdot Spend^{b}$.
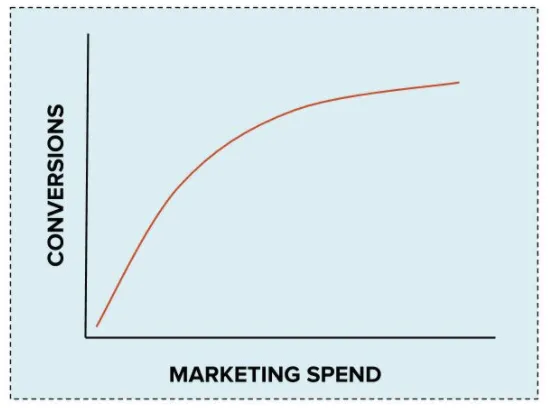
We can fit cost curves at any cohort level, and it's typically done at the granularity of a channel or campaign. Simply put, if for a given campaign we spent $x$ amount of money, and that brought us $y$ users, we have one data point, $(x, y)$.
However, when allocating budgets at a later stage, we might need to make decisions at the campaign level, which cause problems with insufficient amount of data. In the DoorDash Engineering article, Aman Dhesi explains this problem:
For some channels like search engine marketing, we have thousands of campaigns that spend a small amount of money every week. This makes the weekly attribution data noisy. Some weeks these campaigns don’t spend at all, which makes the data sparse. Using this data as-is will result in unreliable cost curves and in turn suboptimal (potentially wildly so) allocation.
At DoorDash they solve this problem by training separate models which use similar campaigns to fill in the gaps in the dataset with synthetic data. This approach brings with itself certain tradeoffs, described in the original article.
In a similar manner, as described in Building Lyft’s Marketing Automation Platform, data scientists at Lyft would fit an LTV curve of the shape $LTV=a\cdot Spend^{b}$. However, they incorporate an additional degree of randomness by modelling $a$ and $b$ as random variables and estimating their parameters $(\mu_a, \sigma_a)$ and $(\mu_b, \sigma_b)$ from historical data. This helps them implement an explore-exploit approach in the bidding step, by instantiating LTV curves after sampling $a$ and $b$ from their respective distributions. We'll revisit this approach briefly at the end of next section.
As described in Growing Our Host Community with Online Marketing, at Airbnb they face a problem stemming from the nature of their product and the market. When predicting LTV for an Airbnb home listing, two major problems are:
- Ad conversions for hosts are a very rare event. This poses problems with building large enough data sets. It also influences data tracking and attribution, where these systems have to be as precise as possible in order not to lose or wrongly attribute any data points.
- Time from ad impression (user seeing an ad) to conversion (home listed on Airbnb) can be very long, sometimes weeks. This is a problem if you want to optimize and re-budget your campaigns soon after rollout - you simply don't have enough data yet.
In the same post, Tao Cui describes the architecture of each part of Airbnb's marketing platform as well as the motivation for building the entire thing, along with choices of tech stack.
In another article dating from 2017, Using Machine Learning to Predict Value of Homes On Airbnb, Robert Chang describes how they use machine learning (ending up using XGBoost in production) to estimate LTV of each listing. Framing it as a typical regression problem, they use hundreds of features, such as location data, price with all the partial costs (eg. cleaning fee, discounts), availability, previous bookings, to predict revenue from a listing after some fixed amount of time (eg. 1-year revenue). If you're curious, the post also describes some of the pieces of infrastructure used by the system and gives a high-level code examples of training pipeline construction.
In Insights on the Pros and Cons of LTV-based Predictive Models an article from AppsFlyer, we can find a summary of pros and cons of the three common LTV modelling approaches for app-based businesses:
- Retention/ARPDAU model
If we have a fairly old and stable product with some historical data, we can leverage the fact that we know the shape of the retention curve and can fit a power curve to several early-retention data points. We also know the Average Revenue Per Daily Active User (ARPDAU) which tends to be stable over time for most freemium and micro-transaction apps (such as free to play games). With some math we can arrive at an estimate of the expected LTV using these two measures. For example, to estimate LTV by day 90 of user's lifetime we would use the following equation: $$LTV_{90}=ARPDAU\cdot\sum_{d=0}^{90}retention[d]$$ - LTV ratio model
As a simple example, in order to get $LTV_{90}$ we'll use historical data to estimate the ratio $\frac{LTV_{90}}{LTV_{7}}$ and use the observed 7-day LTV to predict the 90-day LTV - Behavior driven/user-level models
We'd use user-level features to train our favorite machine learning model for regression. This is the approach mentioned above in the Airbnb case.
The article further discusses pros and cons of each approach in depth, considering the type of business and the intended use cases for the LTV model.
Now, back to the big picture - we needed LTV estimation in order to predict performance of our marketing campaigns. Once we have satisfactory models in place we can use them to make decisions concerning ad budgets.
Optimizing bidding and budget allocation
Once we have the estimates of performance (ROI) for each campaign, we want to allocate our marketing budget across campaigns so that we maximize the total return on investment.
Depending on the degree of automation, we can use the data science-backed systems to either aid manual budgeting or to automate real-time bidding decisions in a fully automated system.
In the first case, we have a static problem where at some point in time we're looking at a set of channels/campaigns with their predicted ROIs. A set of sortable tables, visualizations and derived metrics can invaluably help campaign managers to optimize their efforts.
On the other hand, in a fully automated system, we can have algorithms bidding and deciding how to spend each dollar in an optimal way. Looking into articles from DoorDash and Lyft engineering teams, we learn about two variations of an approach that sequentially maximizes marginal value of each dollar spent.
In Optimizing DoorDash’s Marketing Spend with Machine Learning the proposed approach looks at cost curves for each channel/campaign, representing the function $Conversion=f(Spend)$. We note that the slope of the curve is monotonically decreasing as we increase spend, meaning that for each additional dollar spent our marginal value decreases - we get fewer conversions per $ spent.
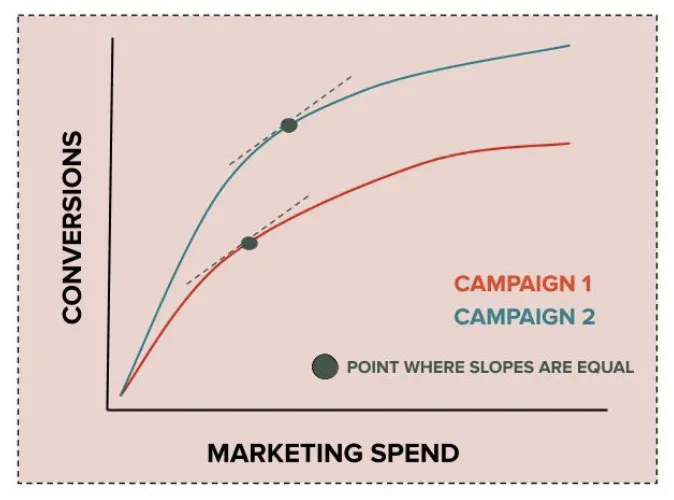
With such problem in place, in order to optimally allocate a fixed budget we can use a simple greedy algorithm:
- For each channel/campaign $c$ set $spend\left[c\right]:=0$
- For each \$ until budget is exhausted:
2.1. Find the channel/campaign $c_{best}$ with the largest marginal return (ie. the largest slope) at it's current spend. More formally: $c_{best}=\underset{c}{argmax}\left\{ \frac{\partial}{\partial spend}Conversion[c](spend[c])\right\} $
2.2. Assign the next \$ to campaign $c_{best}$, ie. $spend\left[c\right]:=spend\left[c\right]+1$
Of course, models and budget allocations can (and should) be periodically updated using performance data obtained from the advertising platform APIs. That brings us to the approach relying on continuously experimenting and updating the model in an explore-exploit fashion.
In Building Lyft’s Marketing Automation Platform, a Multi-armed bandit approach is described. Instead of modeling $Conversion$, they fit an LTV curve, that essentially has the same power-function properties that we described above (monotonically decreasing slope). As mentioned in the previous section, they incorporate an additional degree of randomness by modelling $a$ and $b$ as random variables and estimating their parameters $(\mu_a, \sigma_a)$ and $(\mu_b, \sigma_b)$.
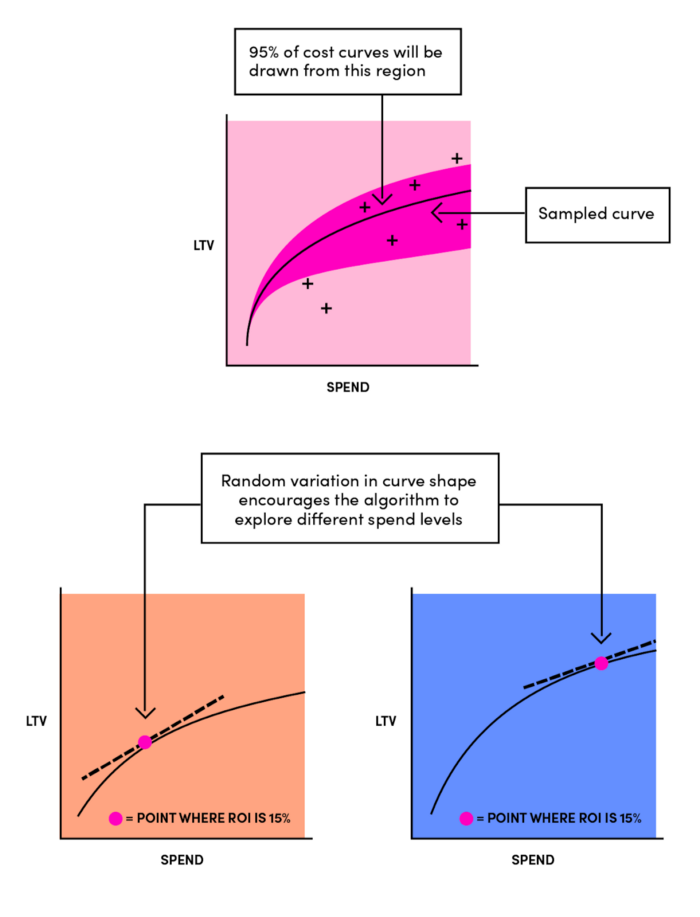
Then they use Thompson sampling, a simple algorithm for Multi-armed bandit problem with a Bayesian model. An excelent introduction to Bayesian bandits and Thompson sampling can be found in Chris Stucchio's article from 2013 - Bayesian Bandits - optimizing click throughs with statistics.
In this article we've covered several case studies in using marketing data science to optimize online marketing with several different approaches. Sources vary in their depth and detail, but it's nevertheless inspiring to learn about all the different ways to solve common problems.
If you're curious about more case studies, make sure to checkout articles similar to Optimizing DoorDash’s Marketing Spend with Machine Learning
Discover the best Machine Learning and Data Science articles from leading tech companies
👋 Liked the article? Let's get in touch - follow me on Twitter @drazenxyz